Speed Harmonization
Smoothing the wave doesn't dissolve the bottleneck.
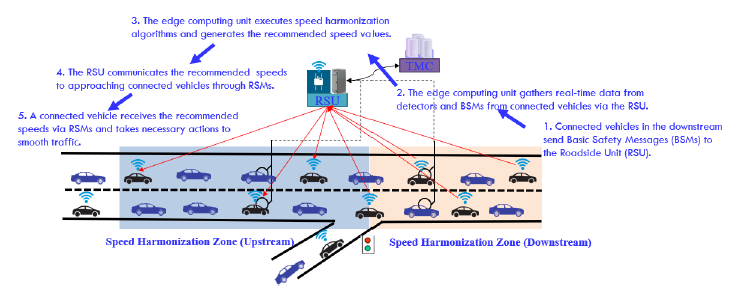
Speed Harmonization tries to dampen stop-and-go shockwaves at freeway weaving bottlenecks by recommending lower speeds upstream — giving downstream merging traffic room to clear. A revised VSL-VSA algorithm drives the recommendations from a blend of detector and BSM data.
How It Works
Each speed-harmonization zone is split into a downstream data-collection segment (2,000 ft past the merging gore) and an upstream broadcasting segment (2,000 ft before it). The edge unit runs a revised VSL-VSA algorithm and pushes recommended speeds via RSMs to approaching CVs.
Collect downstream traffic data
Loop detectors at upstream and downstream VDS positions provide 5-minute occupancy and speed. CVs in the downstream segment broadcast BSMs at 10 Hz with their speeds.
Blend the speed signals
Speed input to the algorithm is v_m = (1−α)·v_det + α·v_BSM with α = 0.1. Detector data anchors reliability (100% observation rate); BSM data captures dynamics.
Decide whether to harmonize
If detector occupancy exceeds 20% (the user-defined threshold), the algorithm activates. Below that, no speed limit is broadcast. At the bottleneck itself, no recommendation — vehicles can accelerate into the freed space.
Broadcast reduced upstream limit
Immediately upstream of the bottleneck, the recommended speed is v_up = β·v_m, where β < 1 controls aggressiveness. CVs receive RSMs at 0.1 Hz, hold the new limit for 10 s, then refresh or revert.
The β knob
- ◇β = 0.95 — gentle reduction. The closest the algorithm gets to neutral, yet still introduces delay.
- ◇β = 0.90 — middle setting. Tested as the default aggression for the published runs.
- ◇β = 0.85 — most aggressive cut tested. Greater upstream speed drop, but no compensating mobility win downstream.
- ◇Occupancy threshold Occ_th = 20% across all runs, near capacity onset.
Test Networks & Scenarios
Test Networks
10-mile · 4-lane freeway · 65 mph
Single representative California freeway segment. 10 weaving sections spaced 1 mile apart, each with an on-ramp pair and ramp meter; RSU communication range 1,640 ft (500 m).
Generation of Traffic Congestion
On-ramp demand bumped to 900 vph at section #10 (vs. 300 vph elsewhere). Metering rate at section #10 set to 900 vph to allow that demand through. The forced bottleneck propagates upstream.
Key Simulation Parameters
Simulation Findings
Across every β setting, demand level, and CV penetration rate tested, the implemented Speed Harmonization algorithm failed to improve mobility — and in many cases increased average delay.
No mobility improvement at any β
β = 0.85, 0.90, and 0.95 all produced equal-or-worse system delay than the baseline. The aggressive reduction (β = 0.85) was the most damaging.
Longer range doesn't help
Extending RSU range from 1,640 ft to 2,460 ft (750 m) at β = 0.95 produced essentially identical results. The algorithm — not the communications — is the limit.
Reducing inflow doesn't free downstream
The core mechanism failed: slowing upstream traffic just before a weaving bottleneck did not create enough space for merging flows to exit faster. Queue Warning's results confirm the same structural issue.
CV penetration sweep is moot
Because the algorithm itself doesn't deliver benefit, increasing the share of compliant CVs from 10% to 50% just amplifies the delay penalty.
Latency and packet loss not tested
Speed Harmonization is not safety-critical and the algorithm aggregates data over much longer windows than communication delay. Communications quality was set aside as a non-factor.
Bottleneck physics resists this lever
Heavy weaving flows at on-ramps create the capacity drop. Reducing upstream throughput is the wrong tool — re-routing the on-ramp demand is the right one.
What This Means
Speed Harmonization is a popular idea that doesn't survive contact with an actuated freeway weaving bottleneck. The mechanism is mismatched to the physics — and the real fix lives elsewhere on the network.
The simulation results are blunt: every parameter setting tested left the system worse off than baseline. This isn't a failure of tuning. It's a structural mismatch — reducing inflow upstream does not create space for downstream weaving flows to clear, because the bottleneck isn't capacity-limited by upstream supply, it's limited by the merge geometry.
Queue Warning's results corroborate this. Slowing upstream vehicles only helps when demand slightly exceeds reduced capacity — a narrow band, and not the regime where most bottlenecks operate. Outside that band, the speed reduction just becomes added delay.
The path forward is demand reassignment, not speed manipulation. Rerouting on-ramp flow at the bottleneck to upstream or downstream on-ramps directly addresses the merging conflict. This is Integrated Corridor Management territory — the next study, not this one.
Deployment Guidance
Do not deploy this Speed Harmonization implementation for weaving freeway bottlenecks. Across all parameter settings tested, it increased average vehicle delay.
For heavy weaving flows, evaluate ramp-flow rerouting instead — directing on-ramp demand to upstream or downstream on-ramps with available capacity.
If pursuing speed harmonization research, focus on bottleneck types other than weaving (incidents, work zones, lane drops) where reducing inflow may genuinely create downstream space.
Don't invest in extended communications range or higher CV penetration for this application. The bottleneck isn't communications-bound; the algorithm is.
Keep the V2X Microsimulation Platform's Speed Harmonization scaffolding intact. Future algorithm variants — including ML-driven or collaborative-control approaches — can be plugged in and re-tested on the same scenarios.